如何儲存 identifier:Cookie 以及那些意想不到的地方 #
此文我們將討論 stateful 的 tracker 可以如何儲存它的 identifier。一個簡單的直覺是,不就存在 cookie 裡面嗎?是的,的確可以儲存在 cookie 內,但我們還有其他地方可以儲存,所以此文將介紹數個常見的儲存位置,以及他們的優劣。
只要可以儲存 identifier,就一定可以作到 same-site tracking,畢竟網站 A 存進去的 identifier,網站 A 當然讀得到。不過 cross-site tracking 卻不是如此,如果要做到 cross-site tracking,則追蹤者需要在不同網站維持同一個 identifier,如此才能知道兩個網站的訪客是同一個人,而在不同網站維持同個 identifier 並不是一個簡單的問題。因為cross-site tracking 的隱私危害遠大於 same-site tracking,故此文也會討論每個方法是否支援 cross-site tracking。其中 cookie 的 cross-site tracking 因為能討論的太多了,所以會放到明天的文章。
Cookie #
若論 stateful tracking,一個簡單的直覺是直接儲存於 cookie 中。確實,identifier 可以直接儲存於 cookie 中。事實上這也是最普遍的 web tracking 形式,更甚至可說是始祖等級的技術。因此這個章節無疑地應該以 cookie 作為開頭。
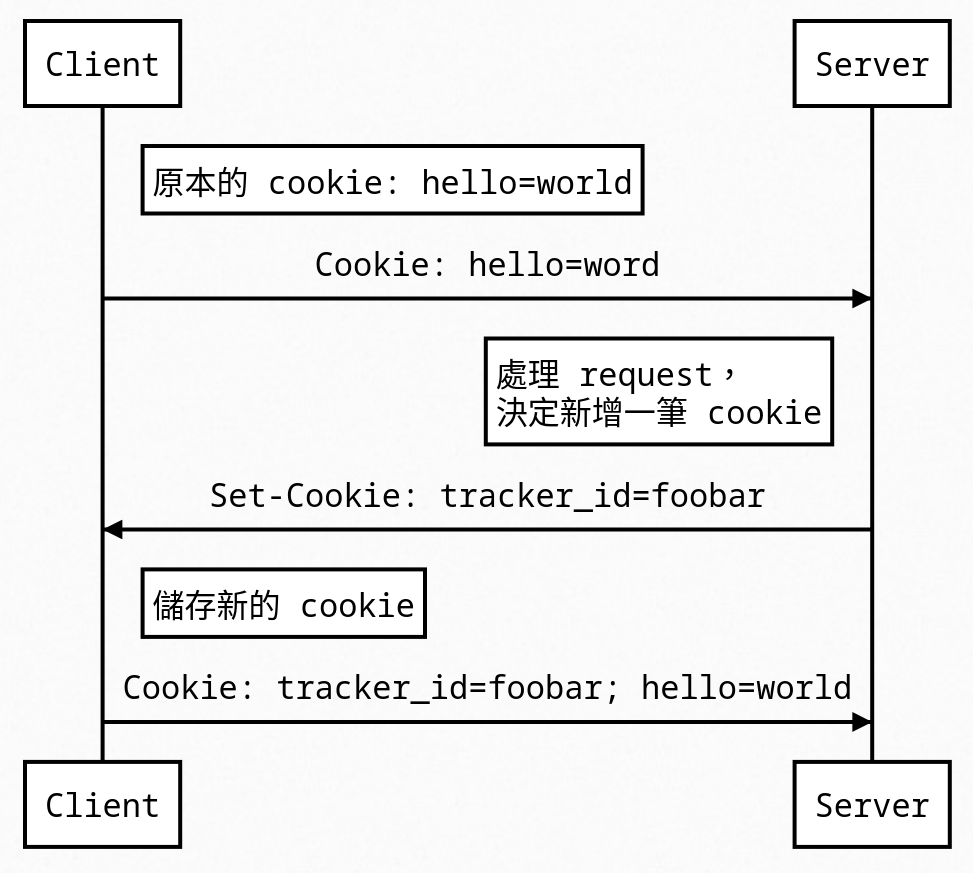
眾所皆知的,HTTP 是 stateless 的,每一次的請求之間都互相獨立。不過總有些情境,我們會希望在 web 上實現stateful 的應用,例如登入網站後,登入狀態應該被保留下來,而不是下一個 HTTP request 時便消失。Cookie 正是嘗試解決此問題。一筆 cookie 是一個簡單的 key-value pair,每個 value 都只能是一筆很小的純文字資料,會夾帶在 HTTP request 與 response 之中,並儲存在瀏覽器裡面。每次發 request 時,瀏覽器便會自動夾帶 cookie,使伺服器得以看到先前儲存在瀏覽器中的資訊;當伺服器回應時,可能也會夾帶 cookie,此時瀏覽器會將伺服器給的 cookie 儲存下來,供未來的使用。基於資安的考量,cookie 儲存以 origin為單位,稱為 Same-origin Policy (SOP)。例如 https://example.com 有自己的 cookie,這些 cookie 只有 https://example.com 可以存取,且只有在對 https://example.com 發出的 request 時會夾帶這個 cookie1,其他 origin 原則上讀不到 http://example.com 的 cookie。
存取 cookie的方式主要有兩種,分別是從 HTTP response 設定以及從 Javascript 設定。
若要使用 Javascript,可以藉由操作 document.cookie 來讀取或寫入 cookie。需要注意的是 document.cookie 有設定 getter and setter,而不是單純的 attribute,所以寫進去的值不會等於讀出來的值。
// Fetch all cookies
let all_cookies = document.cookie;
// Set a new cookie
document.cookie = "tracker_id=foobar; SameSite=None;"
// Set another new cookie
document.cookie = "hello=world; SameSite=None;"
HTTP 的設定方法則是放在 HTTP response header:
Set-Cookie: tracker_id=foobar
經過上面設定之後,之後如果有 HTTP request,就會在 HTTP request header 夾帶 cookie:
Cookie: tracker_id=foobar; hello=world
至此已經可以理解 cookie 如何用於追蹤。當追蹤者發現請求中沒有帶 cookie 時,代表這可能是新的訪客,於是帶入一個新的 identifier,例如 tracker_id=abcde,以後只要伺服器看到 tracker_id 是 abcde,即可知道是之前的某個訪客,並且將不同次瀏覽的資訊連結在一起。
Cookie 可以作為 cross-site tracking,也是最早拿來做 cross-site tracking 的技術。因為能討論的東西太多了,所以明天會有專文介紹 cookie 如何用於 cross-site tracking。
Cookie 作為追蹤方式已經廣為人知,所以有些 anti-tracking 的 extension 會藉由禁止 cookie 來阻擋 tracker(e.g. Privacy Badger),以避免 identifier 被寫入與讀取。此外,也有些使用者或 anti-tracking extension 會藉由刪除 cookie 來移除 identifier。此時追蹤者可能訴諸其他儲存方式。
如果讀者不清楚 cookie 如何運作,還是推薦先閱讀 MDN 上的文件,因為 cookie 會在往後一直被用到。
Local Storage #
Cookie 本來是作為多次 HTTP requests 之間想保留的狀態使用,不需要太多空間,所以就只給了 4KB,但隨著 Web 發展,這漸漸變得是個致命傷,況且有些東西也就只是想儲存在 browser 中,沒有要給伺服器,cookie 在此時就顯得不方便,每次都被夾帶在 HTTP request header 中只會增加網路流量的負擔。
於是之後又出現了一個取代者是 Storage,它同樣是 key-value pair,但可以儲存更多資料,且只儲存於瀏覽器中,不會夾帶在 HTTP request 中傳給伺服器。Storage 又可以分為 Local Storage 與 Session Storage,前者是長期儲存,後者是網頁關閉時就會自動移除。
Local Storage 的操作只能透過 Javascript,大致如下:
// 新增/改寫一筆資料
localStorage.setItem('tracker_id', 'foobar');
// 讀取一筆資料
localStorage.getItem('tracker_id');
Local Storage 作為 identifier 的儲存位置,其使用邏輯基本上與 cookie 類似。不過因為 Local Storage 的值不會夾帶於 HTTP requests,所以如果要與伺服器溝通,需要用 Javascript 讀取後放進 request。其優勢在於通常比較少被封鎖,也相對不容易被刪除,因為很多人都只知道要刪除 cookie 而已。
一個常見的 Local Storage 使用方式是,最初寫入 identifier 時,同時儲存於 cookie 與 Local Storage(以及等等介紹的其他儲存位置)中,往後讀取時主要使用 cookie,但當 cookie 被刪除時,就從 Local Storage 把 identifier 找回來,重新儲存回 cookie。這種藉由其他相對罕見的儲存空間來還原被刪掉的 cookie 的行為,通常被稱為 “respawning”,大概就是狡兔三窟的概念吧。
通常 Local Storage 不會用來達成 cross-site tracking,因為 Javascript 既無法讀到別的 domain 的 Local Storage 內容,其內容也不會被瀏覽器自動帶入於 HTTP request,自然沒辦法拿到別人的 identifier。如果讀者不清楚如何使用 cookie 達成 cross-site tracking,可能會看不懂這個解釋。在明天的文章我們會做更多討論,希望屆時能讓讀者更有概念。
一樣建議如果讀者不清楚 Local Storage 是什麼,可以閱讀 MDN 上的文件,不過 Local Storage 應該這篇之後就不太會提到了。
IndexedDB #
基本上就是又一個可以儲存資料的地方,但比 Local Storage 複雜很多。使用邏輯上是一樣的,所以就不贅述了。如果好奇的話可以讀讀看 MDN 的介紹。
接下來我想進入一些比較瘋狂的部份。因為 HSTS supercookie, document cache, HTTP 301 redirection cache 與 ETag 的 cross-site tracking 方法與防禦一樣,故會統一於文末討論。
HSTS SuperCookie #
HTTP 的 Strict-Transport-Security response header(通常簡稱為 HSTS)是個旨在提升通訊安全的功能,其用於指定哪些 domain 只可以用 HTTPS 存取。如果 example.com 被登記為只能用 HTTPS 存取,則如果使用者嘗試造訪
http://example.com,瀏覽器會自動轉址(307 redirection)到
https://example.com,且這個轉址過程只存在於瀏覽器中,與伺服器無關,於是使用者就不會意外地用沒加密的通道去存取 example.com,確保所有通訊都是加密的。
HSTS 的運作方式簡單來說是,當伺服器以 HTTPS 收到請求時,可以回應一個 header:
Strict-Transport-Security: max-age=<expire-time>
瀏覽器收到後,會將該 domain 加入 HSTS 列表,往後瀏覽器若再次造訪這個 domain,便強制只用 HTTPS 連線,直到過期。需要注意的是,在沒有加密的 HTTP 請求中,Strict-Transport-Security 會被忽略,只有 HTTPS 連線時可以強制要求往後都要 HTTPS 連線。想進一步了解 HSTS,可以參照 MDN 的文件。
但這有一個問題:如果一個 domain 被加入 HSTS,就代表我造訪過該 domain。攻擊者如果嘗試讓使用者造訪 http://tracker.example,因為 HSTS 會自動 redirect,browser 會直接請求 https://tracker.example,攻擊者便可以知道使用者造訪過 https://tracker.example。因此,HSTS 可能洩漏瀏覽紀錄(history stealing)。
這個性質可以被進一步用於儲存 identifier。假設現在追蹤者打算塞一個 5 bit 的 identifier(假設是 10101),追蹤者可以先準備五個 domain [a-e].tracker.example。
當使用者第一次造訪時:
- 追蹤者在網頁中插入 script,browser 發請求給
http://tracker.example/track.js - 追蹤者發現請求是 HTTP,回應第一次造訪時專用的 script,以讓 browser 完成接下來的動作
- 對於 identifier 中為
1的部份,browser 發請求到相對應的 subdomain;例如 identifier 為10101時,讓 browser 發請求給https://[a, c, e].tracker.example/init - 被請求的 subdomain 回傳時夾帶 HSTS,要求以後都要用 HTTPS 存取
- browser 載入
https://tracker.example/track.js,追蹤者在回應中夾帶 HSTS,如此則下次使用者造訪時會直接請求 HTTPS
當使用者再次造訪時:
- 追蹤者在網頁中插入 script,嘗試發請求給
http://tracker.example/track.js,但因為前面 step 5 時有塞過 HSTS,所以 browser 會請求https://tracker.example/track.js - 追蹤者發現請求是 HTTPS,回應再次造訪專用的 script 與其 token,以讓 browser 完成接下來的動作
- Browser 發請求到
http://[a-e].tracker.example/track/<token>,其中有些請求會因為 HSTS 而被改成 HTTPS - 追蹤者會收到
https://[a, c, e].tracker.example/track/<token>與http://[b, d].example.com/track/<token>,藉此還原出第 1, 3, 5 bit 是 1,其餘是 0,所以 identifier 是10101 - 追蹤者可能會想要把 identifier 傳給 browser
同樣是再次造訪,另一種不需要伺服器協助的方式是:
- 追蹤者在網頁中插入 script,嘗試發請求給
http://tracker.example/track.js,但因為前面 step 5 時有塞過 HSTS,所以 browser 會請求https://tracker.example/track.js - 追蹤者發現請求是 HTTPS,回應再次造訪專用的 script,以讓 browser 完成接下來的動作
- 建立 element
<img src="http://[a-e].tracker.example/track.png" crossorigin="anonymous" />,其中有些請求會因為 HSTS 而被改成 HTTPS - 追蹤者會收到收到 HTTP 時回應 A 圖,收到 HTTPS 時回應 B 圖,且兩者都帶 CORS 允許任意 origin(
Access-Control-Allow-Origin: *) - Browser 上的 script 會去檢視每一張圖片的內容,遇到 A 圖為 0,遇到 B 圖為 1,發現第 1, 3, 5 張圖為 B 圖,所以 identifier 是
10101
其中 step 3, 4 的 CORS 設定是為了讓 step 5 時 Javascript 可以讀到圖片內容。
至此我們完成了 HSTS supercookie。上面為了方便解釋,使用 5 bit,也就是最多只能建構出 32 個不同的 identifier,追蹤 32 人。但如果 bit 數增加到 20,也就是準備 20 個 subdomain,就有 2^20 個 identifier 可以用,追蹤超過一百萬人。
一個看似維護資安的功能,竟然可以用於 history stealing 與 web tracking。這件事也不是晚近被發現的,早在 HSTS 標準發展時就已經對於其風險提出警告,在標準化 HSTS 的 RFC 6797 便提到:
Since an HSTS Host may select its own host name and subdomains thereof, and this information is cached in the HSTS Policy store of conforming UAs, it is possible for those who control one or more HSTS Hosts to encode information into domain names they control and cause such UAs to cache this information as a matter of course in the
process of noting the HSTS Host. This information can be retrieved by other hosts through cleverly constructed and loaded web resources, causing the UA to send queries to (variations of) the encoded domain names. Such queries can reveal whether the UA had previously visited the original HSTS Host (and subdomains).
考慮到 HSTS 為資安帶來的效益遠大於可能被追蹤的風險,畢竟後者是匿名身分可能被發現,前者是整個加密通訊會被破壞、被監聽、被中間人攻擊等,風險顯然大很多,因此標準制定者與瀏覽器開發者還是決定導入 HSTS。
不過 HSTS supercookie 也許在理論上可以用,在實際上卻不太可行。首先,因為需要請求 HTTP 資源,如果網站使用 HTTPS,其中的 HTTP 請求可能會被阻擋(現今的 browser 可能會阻擋 mixed content),所以上述方法會因為無法發純 HTTP 請求而失敗 。至於如果網站沒有使用 HTTPS,那也許有遠比 web tracking 更大的資安威脅需要先考慮。此外,大量發送請求也很容易被發現,如上所述,若 identifier 的 space 要超過一百萬,就必須發 20 個請求,雖然這並不是難以接受的巨大成本,但也沒有小到可以忽略。
Webkit 提出了兩種解法。
第一種解法是,只允許當下的 domain 與其 top-level domain 可以設定 HSTS,例如,如果有個使用者在 site.example.com,則只能設定 site.example.com 與 example.com 的 HSTS,不可以為 a.example.com 設定 HSTS。如此則 supercookie 自始便無法寫入。
第二種解法是,當一個 domain 已經被視為嘗試追蹤使用者而被阻擋,在該 domain 會忽略 HSTS 紀錄,所有 URL 都按照他原本的樣子出去,如此則 supercookie 讀到的數值會都是 000…。
Document Cache #
在日常上網時,我們常常會瀏覽重複的網頁,請求一樣的資源。試想一個人在維基百科上查資料,無論他在哪個條目,其實維基百科的標誌圖檔、CSS 檔、JavaScript 檔等可能都是重複的,瀏覽器為了減少流量並加速操作,會把這些檔案儲存下來,下次如果遇到重複請求時,可以使用這些之前存好的東西出來用。這就是所謂的 cache(快取)。
正如其他會儲存資料於瀏覽器內的技術,cache也同樣有可能被用於 web tracking。Cache 用於 web tracking 的方法很多,在此介紹其中三個具有代表性的方法。
第一個方法是,直接把 identifier 存在 cache 裡面。
網站管理者在網頁中插入一段 script,讓使用者去存取 https://example.com/tracking,於是當第一次存取時:
- 瀏覽器看到對
https://example.com/tracking的請求,發現不在 cache 內,於是送出請求 - 伺服器收到請求,隨機生成一段 identifier 放在 response body,然後在 response header 加上
Cache-Control: max-age=31536000,也就是指定 cache 保留一年 - 瀏覽器看到 response header 中的
Cache-Control,把 cache 存起來 - Javascript 讀到請求內容,還原出 identifier
當使用者再次造訪時:
- 瀏覽器看到對
https://example.com/tracking的請求,發現它在 cache 內 - 瀏覽器直接回應 cache 內的資料
- Javascript 讀到儲存於 cache 內的內容,還原出 identifier
HTTP 301 Permenent Redirection Cache #
第二種應用 cache 來儲存 identifier 的方法是,儲存於 redirection 的資訊中,這往往更難發現。
一如剛剛的舉例,網站管理者在網頁中插入一段 script,讓使用者去存取 https://example.com/tracking,於是當第一次存取時:
- 瀏覽器嘗試存取
https://example.com/tracking,發現不在 cache 內,於是送出請求 - 伺服器收到
https://example.com/tracking的請求,隨機生成 identifier,回傳301 Moved Permanently,將請求重新導向到https://example.com/tracking/<identifier> - 瀏覽器收到回應,請求
https://example.com/tracking/<identifier> - 伺服器收到
https://example.com/tracking/<identifier>的請求,把<identifier>放在 response body 內 - 瀏覽器會把這個 redirection 的紀錄 cache 下來
- Javascript 讀到
https://example.com/tracking/<identifier>,得出 identifier
於是當使用者再次造訪時:
- 瀏覽器看到對
https://example.com/tracking的請求,發現之前 cache 裡面說這已經永久重新導向到https://example.com/tracking/<identifier>了,因此瀏覽器直接對https://example.com/tracking/<identifier>發出請求 - 伺服器收到
https://example.com/tracking/<identifier>的請求,把<identifier>放在 response body 內 - Javascript 讀到
https://example.com/tracking/<identifier>,得出 identifier
因為是 301 是永久重新導向,所以這個 cache 原則上不會過期。不過 cache 可能還是會被使用者人為清除,或瀏覽器也有自動清空 cache 的功能。
ETag #
在 cache 的世界,有個難題是:我如何知道 cache 是否過期了?如果網頁已經更新了,瀏覽器卻還提供 cache 給使用者,會讓使用者看到舊版資料,這並不是一個理想的體驗。在 Web 的世界,通常使用 ETag (Entity Tag) 來辨識 cache 是否已經過期。其運作方式是這樣的:
- 使用者第一次存取一個資源(可能是網頁、圖片、影片等)
- 伺服器回傳時夾帶一個 ETag(例如
123),也就是在 response header 加上ETag: "123" - 瀏覽器把資源存進 cache 並註明 ETag 是
123 - 下一次使用者要存取同樣資源時,瀏覽器便在請求中夾帶 ETag
If-None-Match: "123" - 伺服器檢視 ETag 為
123的版本是否還是最新版本 - 如果是,回傳
304 Not Modified並且 response body 為空,瀏覽器就知道可以直接拿 cache 出來用 - 如果不是,就回傳原始檔案以及新的 ETag,瀏覽器就會更新 cache
藉由 ETag,我們可以簡單地確認資源是否是最新版。
但仔細想想,會發現一件事:ETag 可以藉由 HTTP response 設定,並夾帶在 HTTP request,這不就是 cookie 的特徵嗎!?於是我們可以用類似 cookie 的方式把 identifier 放在 ETag 之中,藉此達到 web tracking。
- 使用者第一次存取一個資源(可能是網頁、圖片、影片等)
- 伺服器發現 request 沒有
If-None-Match,所以是新的使用者,自動生成一個 identifier 並夾帶在 ETag 之中,也就是在 response header 加上ETag: "<identifier>" - 瀏覽器把資源存進 cache 並註明 ETag 是
<identifier> - 下一次使用者要存取同樣資源時,瀏覽器便在請求中夾帶 ETag
If-None-Match: "<identifier>" - 伺服器發現 request 有
If-None-Match: "<identifier>",於是就知道這個使用者的 identifier 了,回傳304 Not Modified以確保這個 ETag 會持續被瀏覽器記住
就如同其他 cache 的方法,ETag 固然沒有像 cookie 那麼持久,有很多行為都可能促使瀏覽器默默地把 cache 清空,但在短期的追蹤之中,這仍然很有效。
接著簡短地討論與 cache 有關的三種 web tracking 方法(Document Cache, HTTP 301 Permenent Redirection Cache, ETag)如何用於用於 cross-site tracking。在瀏覽 blog.example 時,會留下一些 cache,在瀏覽 news.example 時,如果又遇到一樣的資源,可能被重新拿出來用。以 HTTP 301 Permenent Redirection Cache 為例,如果在 blog.example,瀏覽器記住了 https://example.com/track 要重導向到 https://example.com/track/<identifier>,到了 news.example,瀏覽器一樣會直接請求 https://example.com/track/<identifier>,因此追蹤者就是知道這個來自 news.example 的請求就是之前 blog.example 的那個訪客。如此便達成 cross-site tracking。
一個簡單的方法是:讓每個 domain 有自己的 cache,在瀏覽 A 網站時留下的 cache 就只能用於 A 網站,B 網站如果請求同樣資源,不能使用 A 網站留下的 cache,只能重新請求。這稱為 “cache partitioning”,如果對這項技術感興趣,可以嘗試了解 Chrome 的 cache parititioning 如何運作。如此雖然會增加一些網路頻寬使用,但可以改善隱私。
結語 #
此文我們介紹了數個可以儲存 identifier 的地方。基本上遠不只這些,還有很多很奇葩的儲存方法,但因為有些相對少見,有些只存在於學術論文中而沒有被實際應用,所以我覺得沒必要在此文中提出(其實更大的原因是我懶得寫),所以剩下就留給讀者自己研究了,如果到後面沒梗可寫了也許我會再回頭補一些有趣的方法。另外是,在遠古時代有個東西叫做 Flash cookie,大概就是使用 Flash 的儲存空間來塞 identifier,但我覺得齁,如果 2022 年了你還在用 Flash,那問題應該不是被 fingerprint 而已了,加上我也沒有環境測試 Flash cookie,所以就先略過了,只是點出這東西具有歷史意義上的重要性。
參考資料 #
Protecting Against HSTS Abuse
Anatomy of a browser dilemma – how HSTS ‘supercookies’ make you choose between privacy or security
No Cookies, No Problem — Using ETags For User Tracking