Topics API #
Google Topics API是一個用於追蹤使用者的瀏覽紀錄,藉此投放使用者可能感興趣的廣告。與 FLoC 一樣,Topics API 透過分析使用者的瀏覽紀錄來推測使用者感興趣的「主題」(所以叫做 Topics),並將其提供給廣告業者,以便投放使用者會感興趣的廣告。Topics API 的推出旨在解決 FLoC 所引發的隱私爭議,它不讓追蹤者自己蒐集數據以追蹤使用者(群)的喜好,而是直接在瀏覽器裡面推測出使用者喜好之後,將推測結果傳給廣告業者,藉此免除這些廣告業者自己部屬追蹤器所可能造成的損傷。
Topics API 如何運作 #
首先,瀏覽器會為每個訪問過的網站分配一個主題,這個主題來自Google 預先整理出的四百多個可能主題列表1。例如,一個 cnn.com 的主題可能是「新聞」,而一個 amazon.com 的主題可能是「購物」。瀏覽器會內建一個很輕量的 ML classifier,這個模型會根據網站的域名來判斷網站的內容。例如 tennis.shop.example 可能會被歸類在「運動」類,但 shop.example/tennis 會因為 classifier 只能看到 shop.example 而被歸類在「電商」類。另外,這個分類是在客戶端完成的,所以其他人不會知道使用者造訪了哪些網站。
瀏覽器會將使用者的瀏覽紀錄轉換為一個主題的歷史紀錄。主題歷史紀錄是一個列表,其中包含了使用者瀏覽過的所有網站的主題,以及每個主題出現的次數。
接著,在每一個週期(epoch,目前定義是一週),瀏覽器會計算好五個最感興趣的主題給個別網站。每次網站呼叫 document.browsingTopics() 要求主題時,瀏覽器有 95% 的機率從五個最感興趣主題中選一個回傳,又有 5% 機率會隨機找一個主題回傳。接著在這個週期內,同個網站每次回傳的主題都會是一樣的,不同網站可能回傳不同的主題,但都是由那五個最感興趣主題中選出來的。無論是真的還是隨機的,這個主題會維持在主題列表中三週。
在下一個週期時,網站如果又請求了主題,瀏覽器會多給網站一個主題(一樣有 5% 是隨機選的),於是此時網站可以看到兩個不同主題。這個過程會一路重複到列表超過三個主題,也就是最早加入的主題已經存活達三週了,則會把最早的主題移除,以確保任何一個時間點網站能查到的主題至多只有三個。
以下表舉例(實際上主題列表並未排序,為講解方便故表中有排序):
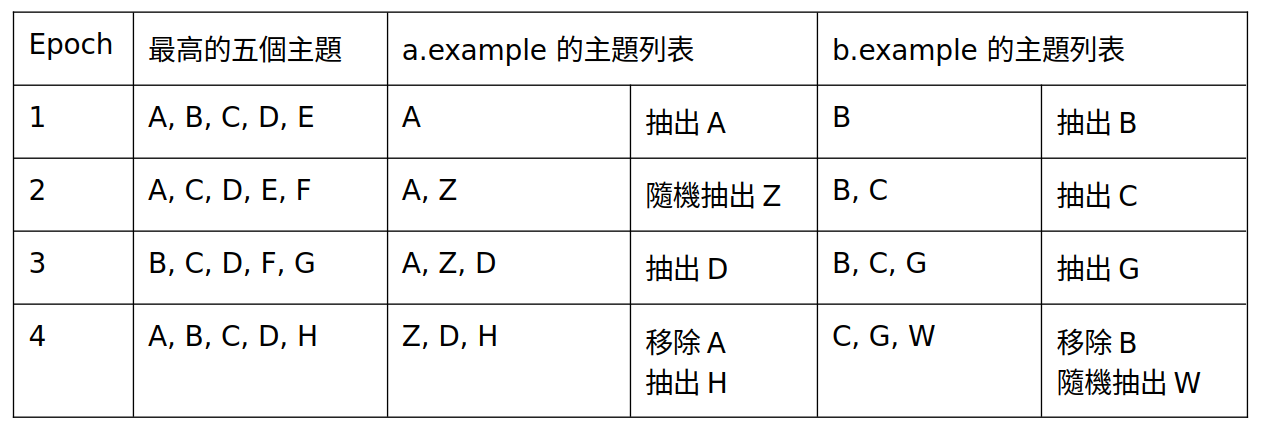
之所以會存在 5% 隨機選擇的主題,可以從兩個不同角度來講。首先,這個做可以確保每個主題都會有夠多人,不會有冷門到只有少數幾個人的主題。此外,這樣的設計還提供的可否認性:如果使用者被發現喜歡某個主題,他可以宣稱這是被隨機選的而非他真的喜歡,而且其他人不會知道這是不是真的隨機選出來的。另外,從五個主題隨機選以及 5% 隨機主題也確保了主題列表無法被用於 cross-site tracking。
值得注意的是,只有使用者明確造訪的網站會被納入主題計算(例如點擊連結或直接打網址),iframe 裡面的瀏覽不會被納入計算。此外,網站可以看到的主題是由 top-level domain 決定的,也就是 blog.example 如果包含的 tracker.example 的資源,這個來自 tracker.example 的資源看到的主題列表等同於 blog.example 的主題列表,而與 tracker.example 本身作為 top-level domain 時的主題列表不同。
此外,只有觀察到使用者在過去三週內訪問過的主題的追蹤器才能接收到該主題。例如,如果有個追蹤器過去三週從未出現在我瀏覽「新聞」類型的網站,則當這個追蹤器請求主題列表時,它不會收到「新聞」這個主題。這種過濾機制確保只有 tracker 實際觀察到的主題才會揭露給 tracker。為了混淆資訊,機率 5% 的隨機主題不受此過濾影響。
隱私分析 #
Google 提出 Topics API 旨在解決針對 FLoC 的隱私批評,他們也對於 Topics API 提供了一些隱私分析。同時,Mozilla 與 Brave 的研究員們同時也對 Topics API 提出了一些疑慮。在此節我們一一來看這些分析內容。
Topics API 用於 Cross-site Tracking 的可能性 #
FLoC 的一大批評是它可能被用於 cross-site tracking,對此 Topics API 使用了三種機制來減少資訊洩漏,藉此增加 cross-site tracking 的難度。
首先,不同的網站在同一個週期內接收到的主題列表並不一定相同,所以網站A上的使用者主題列表通常不會剛好等同於網站B上的主題列表,所以不會形成 cross-site 的 identifier。
此外,因為主題列表每週只更新一次,所以要蒐集到足夠多資訊,會需要很久。
最後,因為存在 5% 的隨機主題,使主題列表有更大的隨機性,無法直接用於 identifier。即便攻擊者暗中紀錄過去出現過的所有主題,當趨近無限多個週期之後,所有使用者曾經出現過的主題都會是一樣的。
理論上,這些設計應該使得 Topics API 用於 cross-site tracking 並非易事,但這也不表示就毫無可能。更甚至可以說,如果攻擊者可以建構出一個移除雜訊的主題列表,則會有 cross-site 的特徵,雖然這個特徵可能沒有獨特到可以直接作為 identifier,但如果再搭配 IP address 以及 browser fingerprinting 等傳統特徵,則有可能建構出足夠獨特的 identifer。在後文我們會討論更多移除雜訊的可能性。
Topics API 洩漏資訊量不會比 Third-party Cookie 多 #
對 FLoC 的一個重要批評是,如果 tracker 未曾出現在使用者 A 瀏覽的新聞網站,它可能因為使用者 B 常常瀏覽新聞網站,而且 A、B 兩人在同個 cohort 內,所以得知 A 也愛瀏覽新聞網站,這使得 FLoC 洩漏了 third-party cookie 本不會洩漏的資訊。為了避免類型的問題,Topics API 限制 tracker 獲得的主題列表中,不會出現它未曾得知使用者存取過的網站主題,以上例來說,因為 tracker 未曾學到使用者 A 瀏覽新聞網站,所以 Topics API 回傳主題列表時,不會讓 tracker 知道使用者 A 對新聞感興趣。
避免讓 Third Party 對使用者行為做分析
此外,不同於過去 third-party cookie 讓追蹤者可以看到所有使用者行為,並自己去分析使用者的喜好,因為 Topics API 只會揭露固定那些主題給廣告投放者,而且其主題判斷還只根據網域,不根據網站內容,所以 tracker 可以學到的資訊會被限縮在非常粗略的主題分類,而且很難推測網站內容。
具備充分的可解釋性與可控制性 #
相較於一堆 identifier,使用者可以輕易理解自己被推測喜歡的主題,為什麼被推測喜歡這些主題(畢竟就只是基於瀏覽紀錄的統計結果而已),並且刪除那些他們不想被投放廣告的主題。這使得使投放廣告的選擇變得可解釋,而且使用者也能控制資訊洩漏。另外,當使用者清除瀏覽紀錄時,主題列表也會清空,確保瀏覽資訊有被確實清理乾淨,不會意外洩漏。
這麼做的一大好處是,使用者如果認為特定主題太過敏感,他可以手動移除這些主題。而且 Google 在挑選主題時也已經先把多數人認為敏感的主題移除了,所以手動移除不恰當的主題不會太費心。不過這也意味著,相較於過去我們可以單方面地指責追蹤者不該任意蒐集使用者資料,現在使用者必須為保護自己隱私付出更大的心力,而我們又知道多數使用者並不會想去改預設設定,這樣的設計可能使得廣告商可以更正當地濫用這些資料,並且把責任推卸給使用者說是他們自己不改預設設定的。長遠來看,我不認為這必然地可以保護使用者隱私。
攻擊 #
若要使用 Topics API 作為追蹤工具,第一步便是要把那 5% 的隨機主題 \(t_{rnd}\) 移除。一個很直觀的攻擊是,攻擊者可以透過每個主題出現的次數來作統計檢定,識別出隨機主題 \(t_{rnd}\) 。試想,當抽到 5% 給出隨機主題時,一個隨機主題出現的機率是 \(p_{rnd} = p / N_{topic}\) ,當抽到 95% 給出正確主題時,一個主題出現的機率是 \(t_e\) 。因為是 \(N\) 個週期隨機抽,每個週期抽一次,所以是個 \(N\) 次的獨立伯努利試驗,我們可以直接算出一個主題在 \(N\) 個週期之後出現在主題列表的超過 \(f_{rnd}\) 次的機率:
\[p_{rnd} (f_{rnd}, N, p_{rnd}) = 1 - \sum_{k \in K} (N, k) p_{rnd}^k (1 - p_{rnd})^{N - k}\]因此我們可以去找到一個 threshold \(f_{min}\) 使 \(p_{rnd}\) 小於一個特定機率 \(p_{min}\) ,這個機率類似於 p-value 的概念,表達該主題出現這麼多次的機率要低到什麼程度時,我們才會相信這個主題不是隨機抽的。如果有個主題 t,在 N 個週期內出現的次數小於 \(f_{min}\) ,則我們可以猜測它是隨機的,直接將其排除。這麼做並不保證一定會還原出真正的主題列表,可能會排除一些相對罕見但真的主題,不過這也沒關係,正如我們在 browser fingerprinting 時討論過,特徵只需要是穩定且獨特即可,不需要是真的。
藉由這個方法,Jha 等人發現,在小規模的實驗環境中,可以很穩定地重新識別一部分的使用者(大約 15%),雖然效果肯定不如 third-party cookie 那麼強,但也顯示了 Topics API 並非完全不可能用於針對個人的 cross-site tracking。不過無疑的,Topics API 大幅改善了現有追蹤技術的缺點,在這點上仍然是個巨大的進步。