FLoC,以及它為何失敗 #
此一系列的第一篇文章就要來看個失敗的案例:Google 的 FLoC(Federated Learning of Cohorts)。說它失敗,是因為其在 2020 年被提出後便遭遇許多攻擊與質疑,認為其可能非但沒解決問題,還加劇隱私侵害,隨著攻擊越來越強烈,最後 Google 在 2022 年 1 月宣佈放棄 FLoC,並提出取代之的 Topics。
也許讀者會趕到疑惑,為什麼要用 FLoC 這種已經被棄用的案例來開啟這個章節。其理由有二,首先是 FLoC 的設計邏輯非常有趣,至少在我眼中它所使用的演算法非常優雅;第二點是,FLoC 的設計乍看之下應該很安全,其隱私保護也有理論保證,於是為何它引發爭議、被認為侵害隱私,就成了一個有趣的問題。
FLoC 是什麼?想解決什麼問題? #
Google FLoC 旨在取代 third-party cookie,成為下一世代的 cross-site tracking。重述過去一再提到的,third-party cookie 的功能之一是,藉由在網站埋入 tracker,追蹤者可以知道個別使用者瀏覽的網站並推測使用者興趣,但隨著 third-party cookie 將要被封鎖,追蹤者還是想要知道使用者興趣,故需要有個方法持續達成推測使用者興趣,同時又不能像以前一樣把瀏覽紀錄全部洩漏給追蹤者。
於是 FLoC 的設計者想到,如果追蹤者只是要知道使用者的興趣,為何需要這些瀏覽紀錄?或是說,對於興趣類似的使用者,追蹤者真的有需要知道個別使用者的瀏覽紀錄嗎?對廣告投遞來說,他們真正想知道的只有這群使用者興趣類似,可以投放類似的廣告。這正是 FLoC 所採取的解法。FLoC 全名是 Federated Learning of Cohorts,正如其名,它嘗試把使用者分成各種群組(cohort),於是追蹤者只要追蹤整個群組裡面的人即可,不會知道也不需要知道每個個別使用者的瀏覽紀錄。稍微更嚴謹來說,FLoC 達成了 k-anonymity,也就是每個使用者都藏在一個至少 人的群組之中,他和其他 個人看起來一模一樣。
FLoC 的運作方式 #
在看具體每個 component 怎麼運作之前,先來看看整個系統 high-level 的邏輯。簡言之,FLoC 其實就跟傳統 web tracking 很像,會嘗試賦予使用者一個 identifier。但其不同點有三。
首先,FLoC 的 identifier 並非唯一的,而是會和所有其他興趣類似的人共享一個 identifier,於是當追蹤者拿到 identifier 時,他只知道這個使用者是整個至少 \(k\) 人的群體之中的其中一人,但不會知道是誰,在追蹤者眼中,他和其他 \(k-1\) 人一樣。這個 identifier 被稱為 cohort ID,也就是這個群組所被給定的 ID。以下我會用 cohort ID 來稱呼 FLoC 的 identifer,因為這已經不是傳統 web tracking 意義上的 identifier,而是 k-anonymity 中的 ID,故使用更精準的詞彙。
第二點是,cohort ID 是瀏覽器根據瀏覽紀錄算出來的,其在所有網站上都會拿到一樣的值,象徵著使用者的瀏覽記錄,故追蹤者可以藉由橫跨不同網站的 cohort ID 達成 cross-site tracking,只是在此 cross-site tracking 並不保證是追蹤到同一個人,而是整個群體一起追蹤。
最後,cohort ID 會更新,因為使用者瀏覽的網站會改變,興趣會改變,就算自己不改變,其他人也會變,所以隨著時間推演,分群結果會變得不太一樣,於是 identifier 自然就會跟著變動。在原先 FLoC 的設計,identifier 會一週更新一次。
追蹤者可以使用 document.interestCohort() 來取得 cohort ID,並且做他想做的追蹤。因為會有一大群人擁有一樣的 cohort ID,故追蹤者只會看到整個群組的瀏覽紀錄,並以此做分析,不會知道每個使用者個別瀏覽了哪些網頁。
但這還沒解決問題,如果有個人實在過於獨特以致沒有人跟他共享 cohort ID,這就使 cohort ID 等價於傳統 web tracking 的 identifier,這並不是個理想性質。因此,我們會需要一個集中的伺服器,蒐集大家自己算出來的 cohort ID(記得前面提過,瀏覽器會先根據瀏覽紀錄把 cohort ID 算出來),確定每個群組都有足夠多人,如果不夠多人的話,就會通知這些 browser 改動它們的 cohort ID,藉此合併太小的群組,使群組變大。
接著我們來細看每個部份是怎麼運作的。
Cohort ID 的生成 #
首先,browser 需要先生出 cohort ID 才可以做後續的事情,所以我們就從 cohort ID 的生成開始講起吧。
SimHash #
Cohort ID 使用了一種名為 SimHash 的演算法。SimHash 是種 locality-sensitive hashing,其性質是:類似的內容會有比較高的機率被分類到同個群組(或是更常用的詞彙是 “bucket”)。SimHash 的主要的想法大概是:隨機選多個 hyperplane(以 normal unit vector表示),然後依照輸入(以一個 unit vector表示)在每個 hyperplane 的哪邊,把結果當成 hash。
我們先從一個 hyperplane 開始看起。給定一個 hyperplane,以 normal unit vector \(r\) 表示,輸入(想要 hash 的內容)以 unit vector \(v\) 表示。定義 \(h(v) = sgn(v \cdot r)\) (sgn 是 sign function,輸入為正時輸出 1,為負時輸出 -1,此處不考慮輸入為 0)。我們可以看出 \(h(v)\) 其實只是取決於 \(v\) 在 hyperplane 的哪一邊而已。
我們可以看出任意兩個 vector \(u, v\) , \(h(u) = h(v)\) 的機率為:
\[Pr[h(u) = h(v)] = 1 - \frac{\theta(u, v)}{\pi}\]其中 \(\theta(u, v)\) 是兩者夾角。
把上述操作重複做 \(p\) 次,一直取 hyperplane 並算出對應的 \(h(v)\) ,把結果合併成一個 vector 作為 hash。換言之,定義
\[H(v) \\ = (h_1(v), h_2(v), \cdots, h_p(v)) \\ = (sgn(v \cdot r_0), \cdots, sgn(v \cdot r_p))\]遵循同樣邏輯,因為每次隨機生成 hyperplane 都是獨立的,所以對於任意兩個 vector \(u, v\) , \(H(u) = H(v)\) 的機率為:
\[Pr[H(u) = H(v)] = (1 - \frac{\theta(u, v)}{\pi})^p\]至此我們推出一個重點:越是接近,兩者 hash 一樣的機率會 exponentially 地上升。於是我們只要把 Hash 結果當成 cohort ID 即可,因為瀏覽紀錄(SimHash 輸入)越是接近,cohort ID(SimHash 輸出)越可能一樣。
把瀏覽紀錄轉成 SimHash #
前文講述了 SimHash 如何運作,接著我們要可以把瀏覽紀錄轉成 SimHash。
首先需要把 domain 單向地轉成 vector。其方法是,將 hash 過的 domain 作為 PRNG 的 seed,接著用該 PRNG 從 Gaussian distribution 生出 50 個亂數,合併成一個 50-dimentional floating point vector,如此可以確保同個 domain 一定有一樣的vector,且就算看到 vector 也無法回推原本 domain 是什麼。我們稱之為 domain fingerprint。
我們關注的是整個瀏覽紀錄而不是單一網站,或嚴格來說,過去七天的瀏覽紀錄。所以先對瀏覽過的每個 domain 都做一次上述過程得到其 domain fingerprint,接著其相加,並對每個 element 取 sgn,得出一個 50-dimensional binary vector。
SimHash 的好處是使用者可以獨立計算,不用知道其他人的瀏覽紀錄,且在分群上有可證明的正確性。然而其缺點是,沒辦法保證有足夠多人有一樣的 SimHash,不符合 FLoC 要求,所以單純用 SimHash 不可行。
SortingLSH #
為了解決 SimHash 問題,我們可以對 SimHash 做 postprocessing。試想我們現在有個可信任的資料處理者,大家都把自己的 SimHash 報告上去。該服務接著把每個人的 SimHash 做一次排序(lexicographical sorting),並從頭開始每 k 個不同 hash 包成一個 group,assign 一個 cohort ID,再回傳給大家。這個方法稱為 SortingLSH。其原理正是運用了 SimHash 如果很接近,其原始內容大概也很接近的特色。
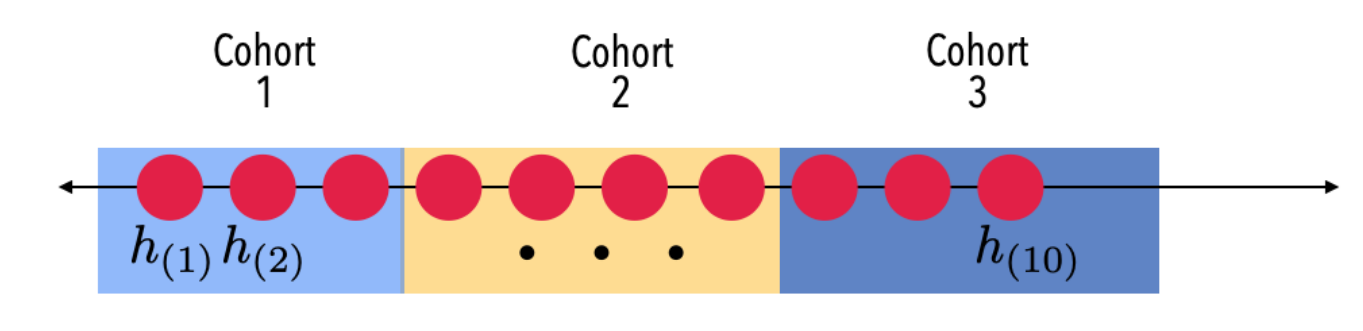
(圖取自
Evaluation of Cohort Algorithms for the FLoC API)
需要注意的是,只有 SimHash 時,cohort ID 是 SimHash 輸出,但為了解決 cohort 太小的問題,我們把 SimHash 聚合起來,並對長得夠像的 SimHash 指定相同的 cohort ID。
PrefixLSH #
但 SortingLSH 還是需要有參數決定 cohort 該有多大,trivially 地取 k 個作為 interval,雖然可以保證 k-anonymity,但不一定能有效地表達 cluster 的概念,尤其當 (k+1)-th 離 k-th 比較近,離 (k+2)-th 比較遠時,直接把 cohort 界線砍在 k-th 與 (k+1)-th 之間不太合理。
PrefixLSH 是個啟發自 k-d tree 的演算法,用於解決此問題。當每個人把自己的 SimHash 提交上來後,可信任的資料處理者接著會根據大家的 SimHash 建立一個 prefix tree,從 root(對應第一個 bit)開始往下走,當剩餘人數還很多時,就開個分支,0 走左邊 1 走右邊,一直開枝散葉直到剩餘人數將要不足 2000 人,如果再分支就無法維持 2000 人以上就停下來,其 prefix 作為 cohort ID 使用。稍微嚴謹一點說,一開始只有一個 interval,如果 interval 夠大就以第 i-th bit 為依據分為左右兩個 interval,直到 interval 不夠大,不再能維持 k-anonymity 為止。接著,資料處理者把建構完的 prefix tree 公布出來,讓使用者計算他的 cohort ID 應該保留多少 prefix。
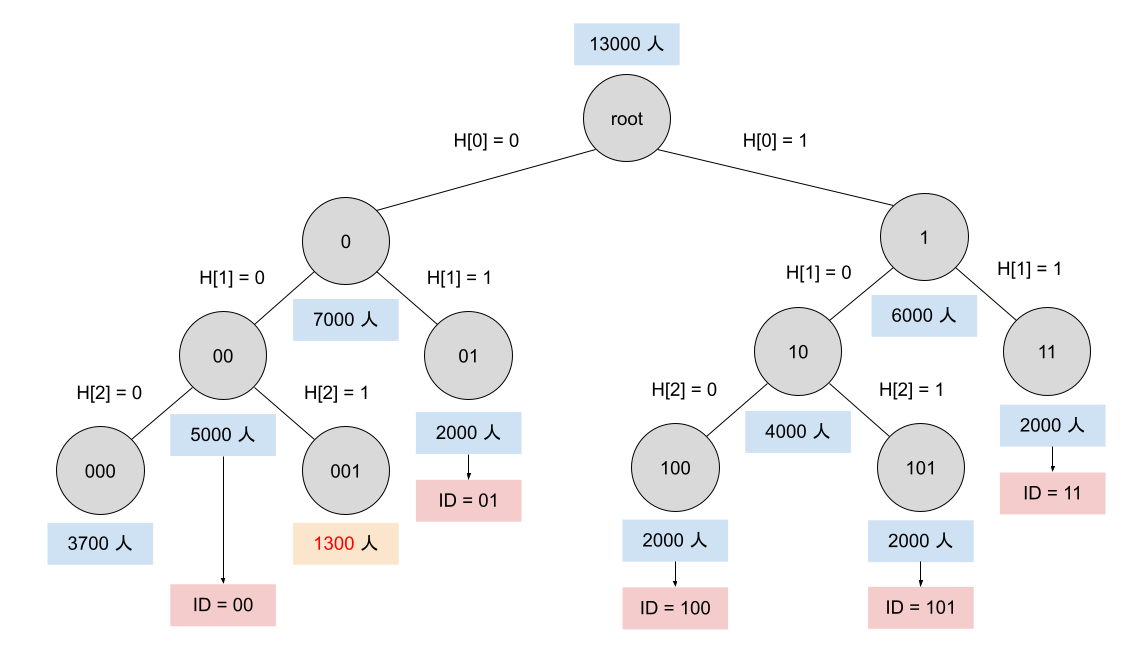
值得注意的是,使用者不需要擔心這個集中的資料處理者會竊取資料。首先,既然資料處理者最後只需要公布 prefix tree,沒有要直接回應給使用者,這意味著使用者可以匿名地提交資訊。更甚至,使用者不一定需要提交他的 SimHash 才可以獲得 cohort ID,只要中央伺服器把最後的 prefix tree 公佈出來,使用者再去檢視他應該屬於哪一群,應該取幾位數的 prefix 即可。換言之,分群只保證了最少有 2000 人,沒有說最多會有幾人,因為也許還有許多人沒提出自己的 binary vector,因此沒有被納入 prefix tree 建構時的人數計算。
過濾敏感資訊 #
可以想像一個情境是:有一整群的使用者都喜歡看色情網站,於是他們就會被聚合在一起,這是一群喜歡看色情網站的人們。被 FLoC 認證愛看色情網站,聽起來不像是討喜的特質。
其解法有二。第一個是,如果 cohort 太接近敏感類型,會直接被移除,拿不到 cohort ID。其主要運用了 t-closeness 的概念,不允許兩個群組太過於接近。第二種方法是,一開始就不要把敏感網站納入一起運算。
以上就是對 FLoC 的技術層面的一些介紹。可能有讀者會問:FLoC 不是叫做 Federated Learning of Cohorts 嗎?Federated Learning 在哪裡?欸… 還真的沒有。
FLoC 的批評 #
在文章開頭提到,FLoC 是個已經被撤回的提案。在理論上 FLoC 的確達到了他所宣稱的 k-anonymity,為什麼這樣的提案會被攻擊?故此章我們將探討,FLoC 究竟哪裡搞砸了。
使追蹤無所不在 #
在傳統 stateful tracking 的時代,只有造訪那些有放 tracker 的網站,使用者才會被追蹤,而且如果兩個 tracker 想要共享資訊,便需要用 cookie syncing 等的方式,更何況 cookie 存取本身就有諸多限制。但 cohort ID 是在所有網站上都一樣的,也不需要特殊權限。於是這下就有了一個在所有網站上都可以用的 identifier 了,連 cookie syncing 都不需要。這簡直就是一個無所不在的 third-party cookie。此時可能有個疑惑是,這的確是一個無所不在的 identifier,但不只一個人使用這個 identifier,而是所有在同個 cohort 的人都共享,即便追蹤無所不在,也不會是個隱私侵害。於是我們就可以進入下一個批評。
基於同質性的瀏覽紀錄洩漏 #
在前文我們不斷強調,因為有許多人共享 cohort ID,所以追蹤者無法還原個別使用者的瀏覽紀錄。這並沒有錯,但問題在於,隱私的界定沒有這麼狹隘。FLoC 把使用者分類成 cohort 的行為本身,其實就已經洩漏許多資訊了。
試想,追蹤者透過各種方法知道了 user A 常常造訪 LGBTQ 交友網站,然後取得了 user A 的 cohort ID。忽然間,追蹤者發現 user B 也有一樣的 cohort ID,於是 user B 就算本來沒被追蹤,追蹤者大概也能猜出他可能時常造訪 LGBTQ 交友網站。
在這個例子中,user B 本來並不是該追蹤者的追蹤對象。在沒有 FLoC 的年代,追蹤者沒在 user B 的瀏覽器中塞過 cookie 也沒做過 browser fingerprinting,所以不會知道 user B 的任何資訊。但有了 FLoC 之後,user B 的瀏覽習慣(LGBTQ 交友網站)反而被洩漏了。而且,如果追蹤者已經從 user A 的瀏覽紀錄知道 user A 的性向,那他似乎也可以大膽地猜測 user B 的性向,這些資訊洩漏都是本可以不發生的。
這種攻擊被稱為 “homogeneity attacks”。
誤認隱私的意義 #
更進一步來說,FLoC 會有上述問題,在於其開發者誤認了隱私的意義,或是給出太過於寬鬆的隱私模型:他們把隱私洩漏侷限在知道個別使用者的瀏覽紀錄,只關注「知道 user A 瀏覽過 LGBTQ 交友網站」這種隱私威脅,而忽略了「知道包含 user A 的一大群人之中,這群人都瀏覽過 LGBTQ 交友網站」也是種隱私威脅。
Homogeneity attacks 在隱私工程其實很常見。許多 k-anonymity 的應用沒有考慮到一個問題是,同質性的所有人可能會有相似的隱私資訊,而他們被分在同一群正好就是因為這些相似的隱私資訊。例如 A、B、C 三人分別有三種不同的癌症,於是做 k-anonymity 後,說 A、B、C 都有癌症,只是不告訴你他們分別有什麼種類的癌症。這的確符合了 k-anonymity 的要求,但這樣做肯定洩漏了一些三人不想洩漏的隱私資訊。
長期的瀏覽興趣追蹤 #
Cohort ID 會變動,而其又反映了使用者的瀏覽紀錄。對於那些使用者有登入的服務,網站可以長期蒐集使用者的 cohort ID,並與追蹤者合作,推測使用者的興趣。這整個過程不需要使用者執行任何 tracker,也不需要儲存任何追蹤者的 cookie 或回傳 browser fingerprint 給追蹤者,只需要網站不斷的存取 cohort ID 就可以完成了。這樣的攻擊得以成功仰賴前面討論到的同質性資訊洩漏,即追蹤者可以藉由追蹤擁有同樣 cohort ID 的其他人來推測所有在 cohort 裡面的人的興趣與可能瀏覽的網站。
這種長期追蹤瀏覽興趣,在過去需要使用者先執行了 tracker,然後期待 cookie 不被刪除、browser fingerprint 不改變,而如今完全都不需要了,只要拿個 cohort ID 就結束了。
沒考慮到 Browser Fingerprinting #
FLoC 的 cohort ID 的確符合 k-anonymity 的要求,但這是建立在沒有任何其他資訊來源下,然而在極為短暫的 privacy engineering 發展,我們已經不斷看到一個看似安全的隱私保護方法,當搭配其他外來資訊時, 可以如何被破壞。在 browser 的情境中,有個很強的資訊來源是 browser fingerprinting。如果追蹤者在蒐集 cohort ID 時,連同 browser fingerprint 一起蒐集,就可以輕易還原出個人的瀏覽資訊的。更甚至,在原本只有 browser fingerprinting 時,一個使用者需要和所有其他人的 fingerprint 都不一樣,才能被追蹤者唯一地識別,但有了 FLoC 之後,cohort ID 已經把使用者分群成非常多小群組,於是 browser fingerprint 只需要不和小群組裡面的其他人重複即可。
換言之,cohort ID 可以貢獻很多 entropy,或是更直白來說,cohort ID + 傳統的 browser fingerprint 就成了超強的、很可能可以唯一識別的 identifier。
Google 的回應是,這可以使用 Privacy Budget 解決,限制 tracker 可以存取的 surprisal 量。但 FLoC 在 2021 年就開始測驗,而 Privacy Budget 還要再等兩年以上才有機會完成部屬,這聽起來很沒說服力啊。
敏感資訊移除太獨裁且沒效率 #
Google 宣稱為了避免使用者因為一些敏感資訊而被歸類在一起,他們會移除那些和敏感內容過於接近的 cohort 或是直接不把敏感網站納入考量。但這麼做既獨裁又沒效率。EFF 的文章用了兩個很貼切的詞彙來形容:orwellian(歐威爾式的)與 sisyphean(薛西弗斯式的)。一方面,Google 似乎可以獨裁地決定哪些內容很敏感,哪些不敏感;另一方面,去找出所有敏感資訊根本是個永無止盡的任務,網路上最不缺的就是敏感資訊。
比較基準 #
Brave 對 FLoC 的其中一個批評是,FLoC 的隱私保護是「相較於 Chrome 而言」。Google 一直都是拿 third-party cookie 還存在、可以用於 cross-site tracking 作為基準來比較,但基本上主流 browser 中只剩 Chrome 還在讓 third-party cookie 做 cross-site tracking,其他瀏覽器如 Firefox、Safari、Brave 等早就對 third-party cookie 有諸多限制或完全封鎖了。換言之,Google 只是讓 Chrome 的狀況從「超級糟糕」變得「沒那麼糟糕」,而其他瀏覽器如果跟進使用 FLoC,反而會讓自身狀況從「還不錯」變成「沒那麼糟糕」,這不是一種進步啊。
我自己認為這不是一種公允的批評。Google 的立場是,我們都討厭 third-party cookie,但如果廣告產業要活下去,應該是使追蹤的同時可以保護隱私,不是讓追蹤完全不可能。Brave 的回應是,我們就是完全不要追蹤。換言之,Brave 給的批評根本不是在同個前提下做的攻擊,以致我認為這個批評是無效的。
Opt-out 制度 #
如果一個網站不希望自身被納入 FLoC 在分群時的考量,需要明文地 opt-out(在 header 加入 Permission-Policy: interest-cohort=())。這一方面是可以理解的,如果讓網站管理者決定自己是否想要參與 FLoC,大概多數人都不會參與,畢竟推播廣告與他們無關。但這形同於將幾乎所有網站都納入一個巨大的實驗,甚至網站管理者自己都不知道他參與了這樣的實驗。這也因此產生了不小的爭議。
結語 #
FLoC 可以說是個教科書等級的失敗。一個在理論上很合理,甚至數學上可證明的隱私保護設計,如何因為錯誤的隱私模型而沒能達成目標,如何在複雜的 browser 環境中搞砸,又如何在技術之外,因為有問題的推行方式而惹毛大眾。
我覺得 EFF 在他們文章結果寫得很貼切:這(有 FLoC 的世界)不是我們要的世界,也不是使用者應得的世界;Google 必須從 third-party tracking 的時代學到教訓,設計出給使用者的瀏覽器,而不是為廣告商而生的瀏覽器。
參考資料 #
Privacy analysis of FLoC - Mozilla
Google’s FLoC Is a Terrible Idea - EFF
Why Brave Disables FLoC
Who is sharing data with Google’s FLoC ad algorithm?
What is FLoC?
Rescorla, Eric, and Martin Thomson. “Technical Comments on FLoC Privacy.” (2021).
Ravichandran, Deepak, and Sergei Vassilvitski. “Evaluation of Cohort Algorithms for the FloC API.” Google Research & Ads white paper, available at: http://githubusercontent. com/google/ads-privacy/master/proposals/FLoC/FLOC-Whitepaper-Google. pdf (accessed 5th February, 2021) (2021).
Epasto, Alessandro, et al. “Clustering for private interest-based advertising.” Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021.
Berke, Alex, and Dan Calacci. “Privacy Limitations Of Interest-based Advertising On The Web: A Post-mortem Empirical Analysis Of Google’s FLoC.” arXiv preprint arXiv:2201.13402 (2022).