Browser Fingerprinting:如何被獨一無二的 Browser 出賣 #
在上一章,我們討論了 stateful tracking、tracker 需要儲存一些 identifier,以及不同隱私保護機制想辦法避免 identifier 被寫入或是存活太久。如果 identifier 其實可以不用儲存,而是用算出來的呢?那是不是意味著 identifier 沒辦法被刪掉,因為只要重新算一次就好了?這就是所謂的 stateless tracking,它有個可能更為知名的名稱:browser fingerprinting。
早從 Web 剛出現的遠古時代開始,為了改善使用者體驗,browser 會傳送一些資訊幫助網站提供客製化的網頁結果。例如:為了提供不同語言的網站給不同語言的使用者,browser 會在 HTTP request 裡面夾帶使用者偏好的語言,也可以在 JavaScript 使用 navigator.languages 拿到偏好語言、為了讓網頁可以根據使用者時區顯示不同時間,可以用 JavaScript 從 new Date().getTimezoneOffset() 拿到時區、為了讓網頁可以根據不同視窗大小調整 UI,可以用 screen.height 與 screen.width 取得螢幕長寬。
其中最重要的資訊莫過於 user agent,它用於表達使用者的作業系統、瀏覽器版本等,如此則當使用者要下載軟體時可以下載到符合其所用作業系統的版本,或是網頁可以針對不同瀏覽器做特別處理,使用一些只有特定瀏覽器支援的功能。User agent 會夾帶於 HTTP requests,也可以用 JavaScript 的 navigator.userAgent 取得。
另外,不同的執行環境也會影響 browser 的性質。例如:不同顯卡或驅動程式在渲染圖片上可能有些微的差異、當網頁指定某個字型時,電腦有沒有安裝該字型會決定 browser 能不能順利顯示、又或是其他硬體設備如電腦的麥克風數量差異。
上面的情境範例都反映一件事:每個 browser 多少有一些性質差異,可能是預設語言、時區或是字體。如果把 browser 的各個性質蒐集起來,便會發現很難在世界上找到兩個一模一樣的 browser。這聽起來很像是 identifier 對吧?我們將其稱為 browser fingerprinting。
Browser fingerprinting 是一種藉由瀏覽器的各種特徵去建構獨一無二的 identifier,並以此識別與追蹤使用者的技術。
Browser Fingerprinting 範例 #
有個很棒的網站叫做 AmIUnique,可以自動對使用者的瀏覽器做幾個常見的 browser fingerprinting 方法,並算出該結果有多獨特。
下圖是我的電腦用 Chromium 算出來的結果:
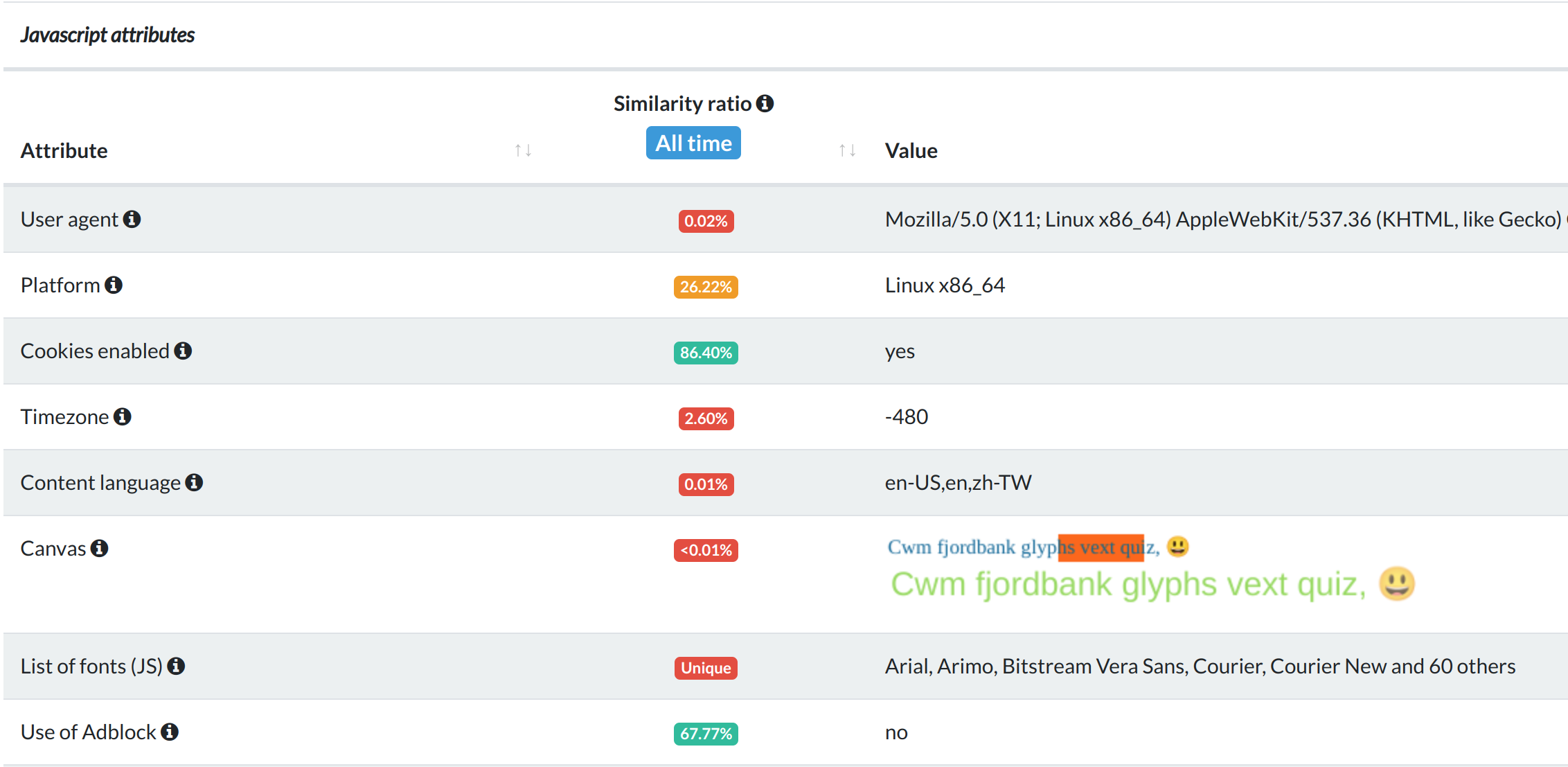
首先可以注意到,我的 user agent 非常罕見:只有 0.01% 的人跟我有一樣的 user agent。光是 user agent 就已經洩漏非常多資訊了。此外,有 28% 的使用者用 Linux,挺沒說服力的,可能因為會用這網站的人都是在乎隱私的技術人員吧。至於字型,幾乎沒人與我有一樣的字型列表。光是從截圖的部份,就可以看出我的瀏覽器有多少特徵是罕見的。更糟糕的是,在我撰文時,該資料庫有接近兩百萬筆 browser fingerprint,但沒有任何人跟我有一樣的 fingerprint,所以我的瀏覽器可以被唯一地識別出來,而這過程中沒有存取 cookie 或其他 storage,也沒有拿取任何特殊權限。
Browser Fingerprinting 特徵的理想性質 #
先前我們提到了多個可以用於 browser fingerprinting 的特徵,例如 user agent 字串、系統語言等,在前面的 AmIUnique 範例中也看到許多不同的特徵。所以為什麼會選用這些特徵?在決定可以使用哪些特徵時,我們應該考慮什麼?我們可以列出三個性質:「可用」、「穩定」、「獨特」。
可用 #
若一個特徵要可用於 browser fingerprinting,第一個要件是 tracking script 必須可以存取該特徵。Tracking script 存取一個特徵時不可以太過於明目張膽,所以該特徵通常不會用到特殊權限,否則跳出奇怪的權限請求,會引起使用者懷疑與反感。此外,必須可以快速地、有效率地存取,畢竟花費兩分鐘並且使 CPU 使用率飆升的 tracking script 將非常明顯。最後,應該在所有情境下都可以使用,不能只有在特定網站或特定狀況下可以使用。
獨特 #
若要識別使用者,特徵自然要足夠獨特。如果所有使用者都沒有啟用 Flash,那「是否有啟用 Flash」大概就不會是個好的特徵,它並不足以分辨使用者。在討論一個特徵是否足夠獨特時,我們時常援引資訊理論來討論每個特徵可以貢獻多少資訊。
穩定 #
如果只要求一個特徵是可用且獨特的,有個完美符合要求的特徵:亂數。任何人都可以存取亂數產生器,只要值足夠大而且亂數夠亂,每個人拿到的數值都會非常獨特。但這顯然不是一個好的特徵,一個一直變化的東西無法作為 identifier。一個理想的特徵應該足夠穩定,每次存取都應該得到一樣或足夠類似的數值,使得其可以作為 identifier。
Browser Fingerprinting 的特性 #
瞭解用於 browser fingerprinting 的特徵應該具備哪些性質後,接著可以得出 browser fingerprinting 的幾個重要的特性。
同時使用多個 Features #
很少會遇到某個特徵可以唯一地識別使用者。舉例來說,很多人的系統語言是波蘭文,也有人的時區是 UTC+11,而作業系統是 Linux 的也有不少,但系統語言是波蘭文、時區是 UTC+11 且作業系統是 Linux 的人很少。基本上現代的 browser fingerprinting 都是非常多特徵的聚合,才能達到理想的準確率。
不需要特殊權限 #
如同前述,browser fingerprinting 所使用的特徵通常不仰賴特殊權限。這些不需要特殊權限的功能之所以存在,是因為一般而言這些資訊不會有危害,也不是設計來做 web tracking 的,所以理應可以放心地讓 JavaScript 讀取,可是這些資訊卻出乎意料地成為可以用於 web tracking 的特徵,或是成為其他特徵的 side channel。因為個別特徵的存取不需要特殊權限,整個 browser fingerprinting 程序當然也就不需要特殊權限,這使得使用者在不知不覺之間就被 fingerprint。
不保證唯一與永久不變 #
雖然前面提到 browser fingerprinting 的特徵講求獨特與穩定,但這只是理想性質,並非永遠可以達成。
首先,browser fingerprinting 所建構出來的 identifier 無法保證獨一無二。雖然機率不高,但的確可能遇到兩個 browser 剛好在這些特徵上完全一樣。在後續章節我們會看到有些 browser fingerprinting 的防禦手法正是建立在創造一模一樣的特徵上。
此外,browser fingerprinting 並不是永久不變的。許多微小的變化都可能使 fingerprint 改變,例如換了一個螢幕、更新驅動程式、更新瀏覽器、裝了一個新的 extension,這些小事都可能讓 fingerprint 改變。不過這並不意味著無法用於追蹤,如果改變足夠小,還是有可能把兩個 fingerprint 連結在一起。在後續我們也會談到如何同時使用 cookie 與 browser fingerprinting 追蹤使用者,藉此延長有效追蹤時間。
難以防禦 #
Browser fingerprinting 非常難以防禦。若說阻擋 third-party cookie誤殺許多正當使用情境,那阻擋可以用於 browser fingerprinting 的特徵幾乎可說是破壞整個 web 生態。拒絕讓網頁存取使用者的時區與語言偏好,拒絕讓網頁渲染圖片,拒絕供網頁使用特殊字型,都將使如今非常蓬勃的 web 生態不復存在。
此外,有許多意料之內與之外的管道可以洩漏資訊。有許多現在很常見的可以用於 browser fingerprinting 的技術,在當初發展時多半從未考慮過可能被用於 browser fingerprinting。只要瀏覽器仍在演進,便會有越來越多功能,也就有越來越多可能洩漏資訊的管道。
儘管如此,仍然有不少有效的防禦手段,只是在這背後有更多已經被證實為無效或甚至有害而被淘汰的手段。抵禦 browser fingerprinting 絕非易事,在往後的章節我們也會做更多討論。
Active 與 Passive Fingerprinting #
稍早提及,browser fingerprinting 的特徵應該要是可用的,也就是容易取得的。我們可以再根據如何取得特徵值,將 browser fingerprinting 分成 active 與 passive。
Passive fingerprinting 所使用的特徵可以直接在網頁請求的內容中看到,不需要另外在客戶端執行程式。常見的如 HTTP request header(其中包含 user agent)、IP address 等。在有些人口較小的情境,光是 user agent 與 IP address 就有機會唯一地識別出個別使用者了,所以即便這兩個特徵看似籠統與無害,在一些情境下仍然可以達成有效的 web tracking。這類型的 fingerprinting 在瀏覽器送出請求時就完成了,在前端幾乎毫無跡象,因此也難以防範。
Active fingerprinting 則是會在網站上插入 tracking script,也就是需要執行一些 JavaScript 來獲得特定特徵。多數 browser fingerprinting 技術都屬於此類型,它們需要在瀏覽器上執行一些程式,這也使得這些行為容易被偵測到並封鎖,但相對的,藉由 active fingerprinting 通常可以獲得更準確與持久的資訊。
Browser Fingerprinting 的防禦策略 #
要如何防禦 browser fingerprinting 而同時不大幅降低使用者體驗,是個艱難的問題。此段我們將只先簡單提出幾個可能的防禦策略。對於個別 browser fingerprinting 技術的防禦將在介紹攻擊手段時一起介紹。更仔細的防禦策略分析則會延後到後續的專章。
前文曾提及,一個有效的特徵應該具備可用、穩定、獨特三個特性,缺一不可。換言之,只要能使其中一個性質消失,該特徵將不再能用於 browser fingerprinting。這正是防禦的三大策略。
第一種策略是移除可用性。換言之,使一個 API 變得不容易存取,或是改成需要特殊權限才能存取。例如 Tor Browser 將 Canvas API、WebAudio API 等功能變成需要授權後才能執行,藉此避免其被用於 fingerprinting。
第二種策略是移除穩定性,也就是使一個特徵的數值變得不穩定,例如加上隨機雜訊。然而,直接加上隨機雜訊不一定有效,因為可能會:
- 洩漏這個使用者正在嘗試避免被 fingerprint;
- 取樣多次後平均,雜訊可能會互相抵銷。
因此更常見的作法是針對每一個 eTLD+1 都有固定的雜訊,且在 cookie 被清空時重置。前者確保 cross-site tracking 無法實現;後者確保 browser fingerprint 最多和 cookie 一樣持久,不會更久,也就使 browser fingerprinting 無法幫助 cookie respawning。
最後則是移除獨特性,也就是讓瀏覽器的行為不再有歧異,若所有瀏覽器的行為都一致,則不再有可供 fingerprinting 的資訊洩漏。
此文是 browser fingerprinting 系列文章的第一篇,也意味著我們告別了 stateful tracking,來到了新的篇章。期待大家會喜歡接下來的文章。
參考資料 #
AmIUnique
Fingerprint Randomization
Browser Fingerprinting: An Introduction and the Challenges Ahead